Análisis eficiente de BigData con data.table
Data.Table
Es un paquete de manipulación de grandes volúmenes de datos que permite eficiencia y efectividad a la hora de gestionar datos. Data.Table es:

. Como data.frame, pero con más poder en la sintaxis de código R, y la implementación de código en C.
. Paquete R en CRAN desde 2006.
Los paquetes de tidyverse tibble + readr + tidyr + dplyr ~= data.table.
tidyverse usa
DF |> … |>, data.table usesDT[…][…]Tidyverse es verborrágico (tiene muchos códigos), data.table es conciso (pocos códigos) por ejemplo: tibble |> filter(x==“a”) |> group_by(z) |> summarise(m=mean(y)) vs: DT[x==“a”, .(m=mean(y)), by=z]Matt habló en el 2014 a usuarios de R
Sintaxis de R con data tablePiensa en términos básicos de unidades: filas, columnas, grupos.
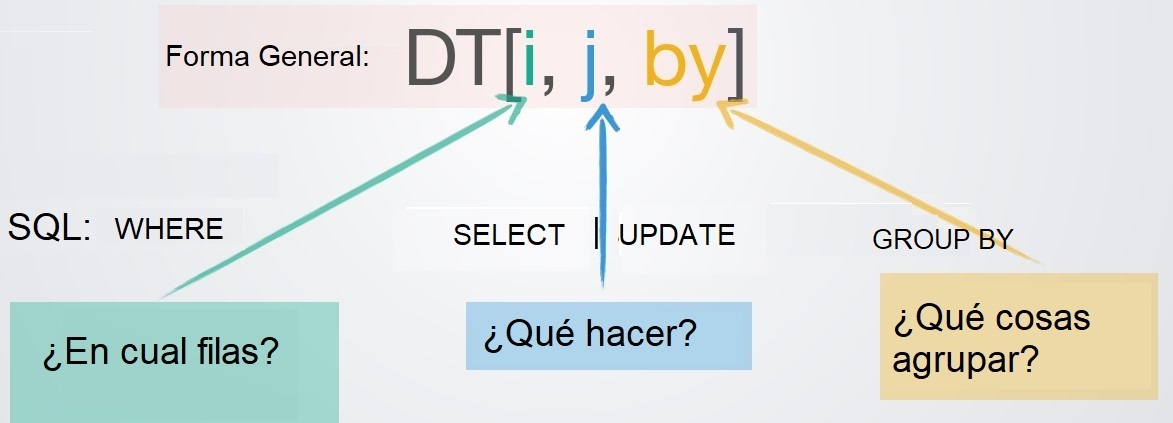
### data.table::fread es extremadamente eficiente en lector de archivos CSV
Lee números reales de CSV, 100 x N
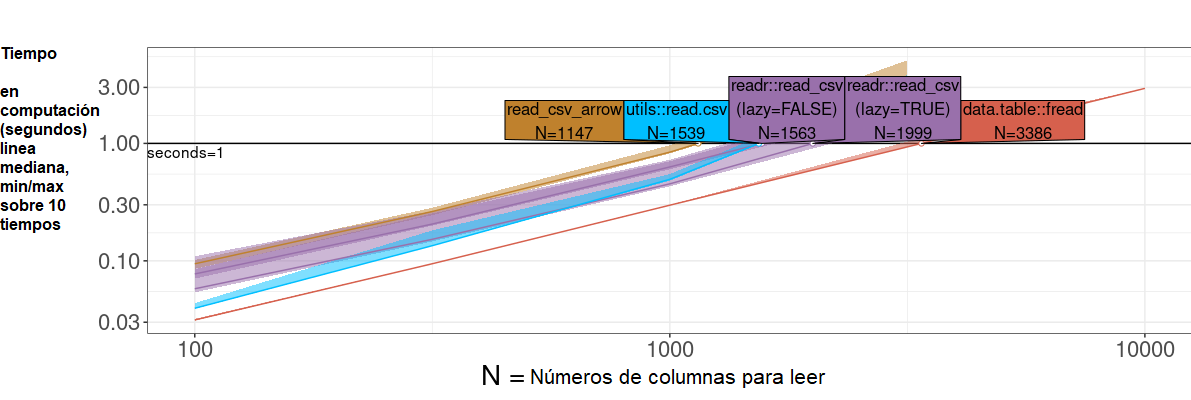
Fuente del código https://tdhock.github.io/blog/2023/dt-atime-figures/